All of them are running, running and running, the long, never ending marathon but what is it with that one lone runner, why isn’t he running?
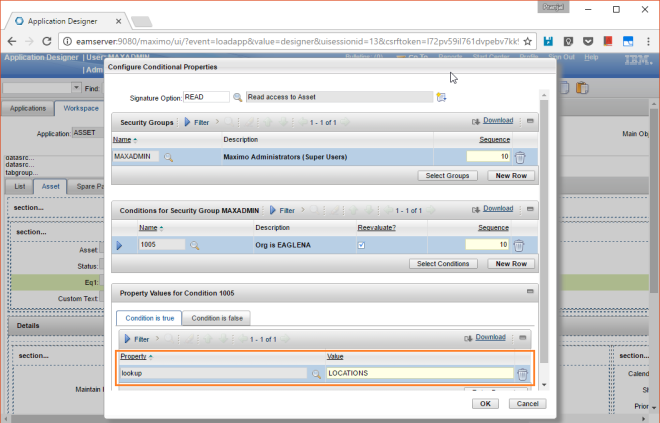
It’s a rare occurrence but you may come across such cron task that is sitting there not executing at all while all the other cron tasks are running just fine! You would see that though it is set to active and the history logs tell you that it started successfully or it was working fine till a certain point but after that there hasn’t been any action.
What is it with this cron task?
It cannot be the admin mode since other cron tasks are running fine. It could be the mxe.crontask.donotrun property but in that case it wouldn’t have started or actioned at all. But better to still double check.
Rare but not impossible, this may be caused by incorrect entry in the task scheduler table.
What is Task Scheduler Table?
The TASKSCHEDULER table is used by Maximo to control the schedule of cron tasks.
Before a cron task runs, Maximo gets the last run information from TASKSCHEDULER table, and if no information is found, it will insert a new record in TASKSCHEDULER table if needed.
For more information about task scheduler table check this post.
What’s the issue with the Task Scheduler?
As I mentioned earlier, the issue may be caused by incorrect entry in the task scheduler table, especially when the LASTRUN is greater than the LASTEND which means the cron task is running or atleast the system thinks that the cron task is running and wouldn’t invoke it again.

This could be because the JVM crashed while the cron task was running and the execution couldn’t complete and so the last run was not updated. It is also possible that the cron task actually got into a hung state during execution.
Another possibility is that there are two entries for the same cron task in the task scheduler table which confuses the system. May be the cron task is running too quickly and it sends an entry twice to the task scheduler, because it didn’t have enough time to complete the first execution. Cron task running on multiple JVM in a clustered environment could also be the cause.
How to fix it?
Delete the entries for the cron task from the task scheduler table. The cron task manager would see that the cron task is active but doesn’t have entry in the taskscheduler so it would create an entry and wait till the next schedule and to run the cron task.
If you want to understand the sequence of events that happens when the cron task starts and shuts down, you can check this post.
Until next time!
Cheers!